Street Scene 3D Reconstruction
Discover how our multi-modal AI pipeline combines Semantic segmentation and Metric depth estimation for comprehensive scene understanding from single images
Introduction
Our Street Scene 3D Reconstruction Pipeline integrates two state-of-the-art AI models to extract comprehensive scene understanding from single RGB images. By combining OneFormer’s universal semantic segmentation with DepthAnythingV2’s metric depth estimation, the pipeline transforms 2D images into rich 3D spatial representations with pixel-level semantic classification. This solution addresses the fundamental challenge of complete scene understanding in computer vision, providing both semantic context (what objects are) and geometric relationships (where they are in 3D space) from monocular input.
Key Features
- Semantic Segmentation: OneFormer model with Swin-Large transformer backbone performs pixel-level scene parsing, classifying every pixel into one of 19 semantic classes (road, sidewalk, building, car, person, vegetation, etc.) following the Cityscapes dataset taxonomy
- Metric Depth Estimation: DepthAnythingV2 with Vision Transformer (ViT-Large) encoder predicts absolute depth values in meters for each pixel, achieving accurate distance measurements from 0.1m to 80m for outdoor scenes
- 3D Spatial Reconstruction: Pipeline converts 2D image pixels into 3D world coordinates by combining predicted depth maps with camera intrinsic parameters, generating dense point clouds where each point retains its semantic class label from the segmentation model
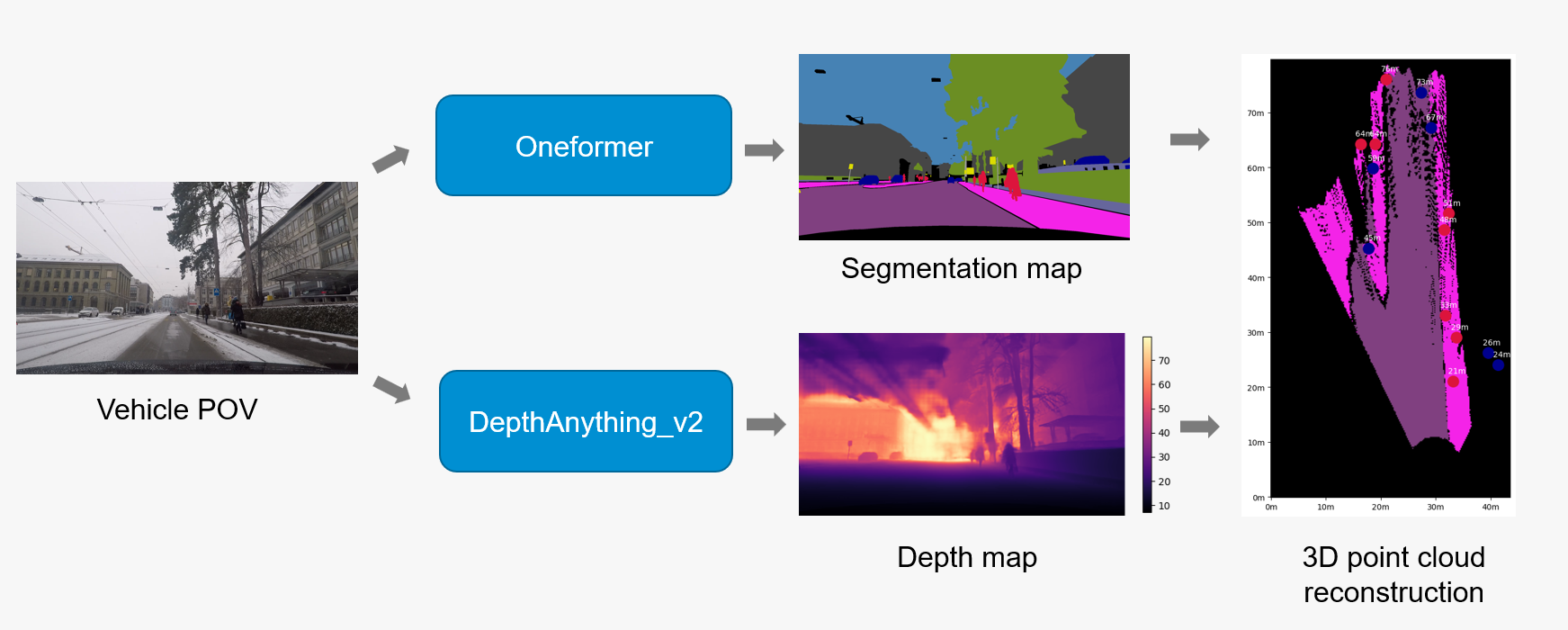
Technologies Used
- OneFormer: Universal image segmentation transformer that unifies semantic, instance, and panoptic segmentation in a single architecture using task-specific queries and Swin-Large backbone (Jain et al., 2022)
- DepthAnythingV2: Foundation model for monocular depth estimation using Vision Transformer encoder with self-supervised learning on large-scale datasets (Yang et al., 2024)
Use Cases
Autonomous Driving Research: The pipeline provides essential perception capabilities for self-driving vehicles by simultaneously identifying road elements, obstacles, and their precise 3D locations. Semantic segmentation distinguishes between drivable surfaces, pedestrians, vehicles, and infrastructure, while metric depth estimation enables accurate distance calculations for path planning and collision avoidance algorithms.
Infrastructure Inspection and Monitoring: The pipeline’s capabilities could enable assessment of road surface conditions and measurement of infrastructure dimensions from standard vehicle-mounted cameras. Such applications might include automatic detection of road defects, estimation of pothole depths, calculation of lane widths, and monitoring of road surface deterioration over time for predictive maintenance scheduling.
Automated Road Maintenance: The system can be used to measure road width and estimate surface depth profiles to optimize road maintenance operation, in particular this was applied in the WINTERAID project to optimize salt spreader operations for winter road maintenance. By analyzing road boundaries through semantic segmentation and calculating precise road dimensions using depth estimation, the pipeline enables autonomous vehicles to adjust salt distribution patterns based on actual road geometry, ensuring efficient resource usage and uniform coverage.
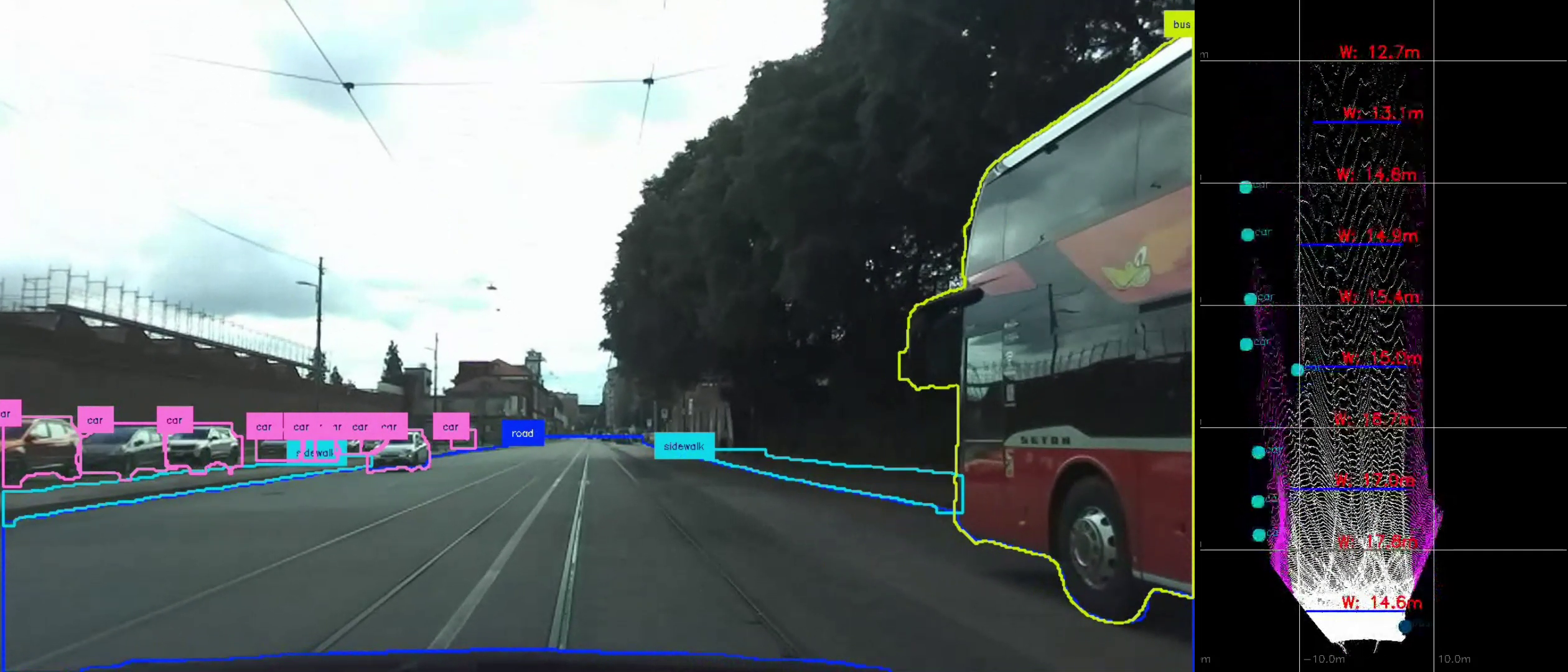
Live Demo
Input
Standard RGB images of outdoor scenes, particularly urban environments and street views. The models accept common image formats (JPEG, PNG) and are optimized for Cityscapes-style imagery but generalize well to diverse outdoor settings including highways, residential streets, and complex urban intersections.
How it works
- Semantic Processing: OneFormer processes the input image through its Swin-Large transformer encoder, generating multi-scale feature representations that feed into task-specific decoders for dense pixel-wise classification across 19 semantic classes
- Depth Inference: DepthAnythingV2 encodes the image through Vision Transformer layers, predicting dense depth maps with metric scale accuracy by leveraging learned representations from large-scale self-supervised training
- 3D Projection: the pipeline projects 2D pixel coordinates into 3D world space using the estimated depth values, creating spatially-accurate point clouds
- Semantic Fusion: Each reconstructed 3D point inherits its semantic class label from the segmentation model, enabling semantically-aware spatial reasoning and analysis
Output
- Dense Semantic Maps: Pixel-wise classifications following Cityscapes taxonomy (road, sidewalk, building, car, person, vegetation, pole, traffic sign, etc.)
- Metric Depth Maps: Dense depth predictions in meters with effective range up to 80m for outdoor scenes
- Semantically-Labeled Point Clouds: 3D reconstructions where each point carries both spatial coordinates and semantic class information
Try it out
Try out the solution in real time on Hugging Face Spaces: